
说在前面
为什么需要全文搜索
如果只是以标题、标签等对文章进行检索,搜索的效果一般较差,用户比较难找到自己所需要的,而全文检索会把文章内容进行分词并构建索引,可以支持大量基于交互式文本的查询,提供高度相关的搜索结果,处理自然语言和模糊匹配等问题。当然它也需要额外的存储空间和维护成本,对于结构化数据的搜索效率不如关系型数据库。全文检索的常见搜索引擎有Lucene,Solr,ElasticSearch等。
Algolia是什么
Algolia是一个提供软件和工具的托管搜索引擎,可以帮助你在你的网站和应用中实现高效、灵活和有洞察力的搜索。Algolia由两部分组成:搜索实现和搜索分析。Algolia还提供了自然语言处理、个性化、动态重排等功能。Algolia每个月为数千家公司提供数十亿次查询,无论在世界哪个地方,都能在100毫秒内提供相关结果。
也就是说我们只需要向algolia提供我们的数据,algolia会自动帮我们构建索引并提供查询的api,这样本地服务器的压力相对减轻,搜索性能也得到了保证,而且它提供的免费计划对于我的小型博客项目是完全够用的,algolia提供了丰富的示例、Api、前端组件库来方便用户将Algolia整合到他们的项目中去,现在我们能见到的很多静态博客、文档类项目都支持了Algolia。
为什么选择Algolia
如果要给我的go项目引入全文搜索的功能,一种途径我们可以使用上述提到的ElasticSearch这类成熟的搜索引擎,但ElasticSearch是需要单独部署的,显然不适合我的小型博客类项目;第二种途径是使用社区的一些全文索引的库,可以直接整合到自己的项目里,这是我的待定途径,如果Algolia不满足要求我便会用这种方法;第三种途径便是接入Algolia这类第三方的搜索引擎服务提供商,我们只需要这项目里封装Algolia提供的Api,再文章处理时适时的构建、更新或者删除索引即可。
Algolia的计划对比
这里只列出几个比较重要的
| 特点 | 免费计划 | 收费计划(Grow/Premium) |
|---|---|---|
| 搜索API | ✔️ | ✔️ |
| 预构建的UI库 | ✔️ | ✔️ |
| 搜索分析 | ✔️ | ✔️ |
| 每个用户的最大应用数 | 1个 | 不限 |
| 每个应用的最大索引数 | 10个 | 50个/1000个 |
| 索引大小限制 | 1GB | 100GB |
| 应用大小限制 | 1GB | 100GB |
| 每条记录的最大大小 | 10KB | 10KB平均值,100KB最大值 |
| 每秒最大查询数(QPS) | 3 | 不限 |
| 无活动停用限制(Inactivity Limit) | 30天无活动停用 | 无限制 |
总结就是免费计划对我来说完全够用了,现阶段使用algolia挺不错的
如何使用Algolia
注册账号、获取appID、apiKey
之前看到的教程说Algolia需要申请资格什么的,我在实际操作过程中完全没有看到这个,可能时最近取消了资格要求吧
注册或登录账号→Sign in | Algolia
我是使用的GitHub账号登录注册的
创建应用
第一次进入可能是他的Get Start页面,直接无视,你的任务只有一个那就是创建应用,左下角
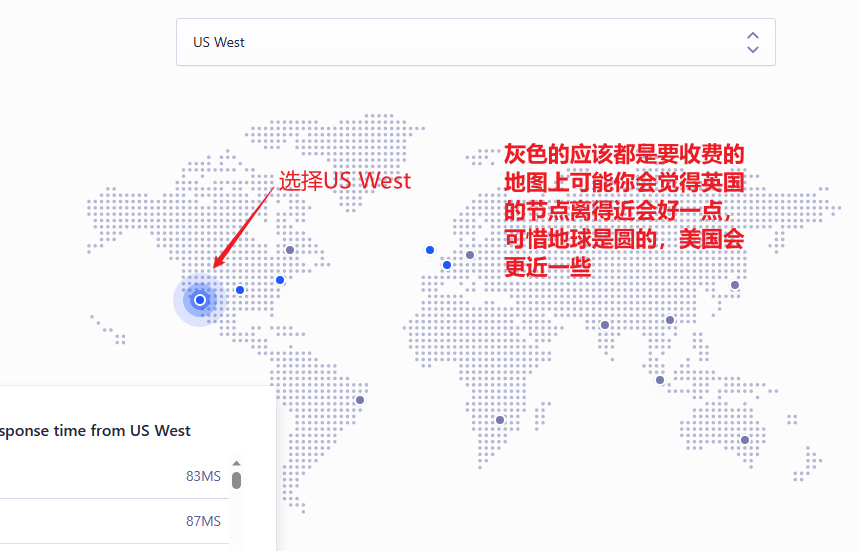
Setting→Applications→Create Application,起个名字,选择Free计划再Next Step这时候我们进入了选择数据中心位置的页面,灰色的都是要收费的,我这里选择US West节点
![选择数据中心]()
选好,下一步,勾选
I agree ...→Create Application,OK,你已经快完成了。选择左上
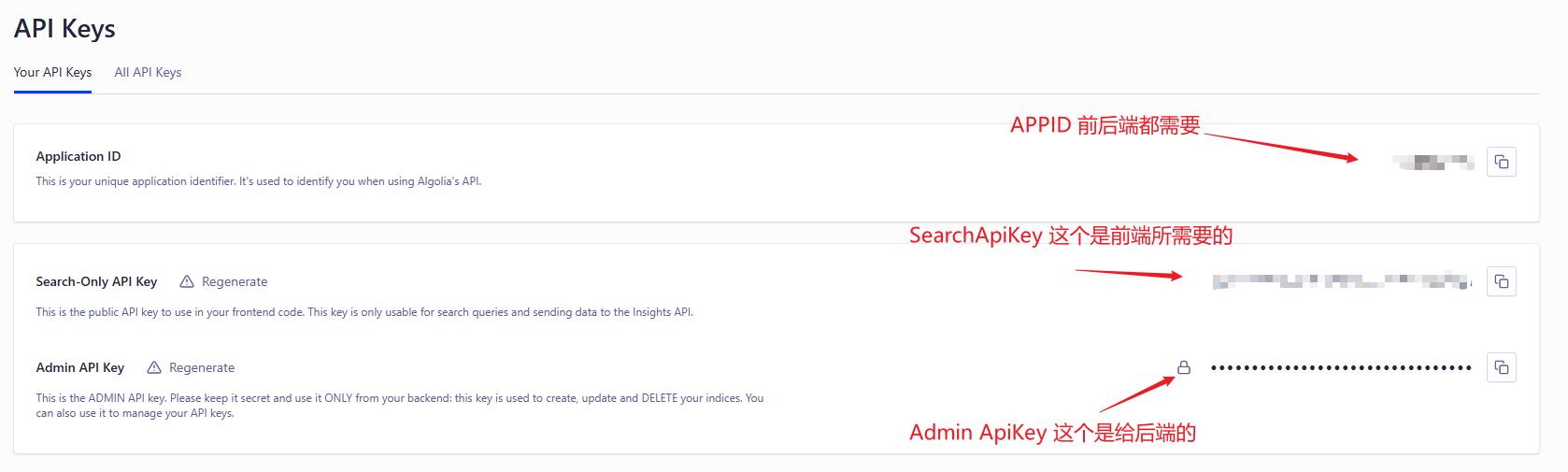
Overview→Api Keys,这时候你应该就可以查看跟复制你的appID与apiKey了,注意它们的用途。![找到API key]()
![注意功能]()
后端处理
Algolia提供了大量的api接口和SDK非常方便你在项目中引入(如果你是hexo、hugo、vuePress这类已经整合了algolia或又相关插件的,那么上一步获取到appid和apiKey就已经可以去使用了)
有教程说使用docsearch-scraper来直接爬取数据的,我感觉多少有点小题大作了,既然都能部署docsearch-scraper了,那完全可以去部署个ElasticSearch来实现全文搜索了,这与使用algolia的初衷多少是有些违背的
我这里以go语言为例,演示一下后端应该有的逻辑
首先我们要导入Algolia的Go的sdk, 这提供了很多方法让我们操作索引
go get github.com/algolia/algoliasearch-client-go/v3
我的项目需要检索的数据就是我的文章,需要对标题和文章内容来构建索引,那么我们提交给Algolia的数据结构应该是这样的
type artObject struct {
ObjectID string // 必须的,这是algolia每一条记录的唯一标识
ID int // 文章的id,这里主要是用于前端来访问到文章页面
Cid int // 文章分类的id,可以使得前端获取到分类的信息
Title string // 标题
Content string // 内容
}我们创建一个方法来获取索引实例
// NewEngine 获取一个搜索引擎的实例
func NewEngine(AppID, ApiKey, IndexName string) (*SearchEngine, error) {
se := new(SearchEngine)
se.ApiKey = ApiKey
se.IndexName = IndexName
se.AppID = AppID
client := search.NewClient(AppID, ApiKey)
//IndexName是可以随便取得,如果不存在就会自动创建
index := client.InitIndex(IndexName)
// 我们只需要index对象
se.Index = index
// 检查连接是否成功
_, err := index.Exists()
return se, err
}为了获得更好得搜索效果,我们还需要对索引的设置项进行初始化
// InitEngine 初始化引擎,主要是进行设置项的初始化,一般只需要执行一次
func (se *SearchEngine) InitEngine() error {
index := se.Index
if _, err := index.SetSettings(search.Settings{
// 设置检索的条目
SearchableAttributes: opt.SearchableAttributes(
"content", "title",
),
// 设置结果的排序依据
Ranking: opt.Ranking(
"desc(id)",
"typo",
"geo",
"words",
"filters",
"proximity",
"attribute",
"exact",
"custom",
),
// 清空highlight(因为我们不需要这部分数据)
AttributesToHighlight: opt.AttributesToHighlight(),
// 设置简写,优化性能(返回经过简化处理的文章,截取命中关键词的那串文本)
AttributesToSnippet: opt.AttributesToSnippet(
"content:60",
"title:30",
),
// 取消content优化性能(不返回完整的文章内容)
AttributesToRetrieve: opt.AttributesToRetrieve(
"title",
"id",
"cid",
),
}); err != nil {
return logError(err)
}
return nil
}写一个新建索引的方法, 删除等也是同理
// SaveArts 构建文章的索引
func (se *SearchEngine) SaveArts(arts ...SearchArt) error {
index := se.Index
var objs []artObject
for _, v := range arts {
var obj artObject
obj.ObjectID = "art" + strconv.Itoa(v.ID)
obj.SearchArt = v
objs = append(objs, obj)
}
if _, err := index.SaveObjects(objs); err != nil {
return logError(err)
}
return nil
}最后我们要在发布文章、修改文章、删除文章等需要对索引进行操作的位置引入方法。这样我们后端的逻辑就基本完成了。
前端处理
前端是最容易的,因为Algolia提供了几个现成的ui组件,我们直接按照教程在前端页面引入即可,这里同样也需要填写appID、apiKey与IndexName,注意这里的apiKey是search apiKey千万不要把你的admin apikey暴露给前端了。官方的InstantSearch.js、与autocomplete都挺不错的,也有官方的示例来方便你使用。
我的项目前端是对InstantSearch.js进行了简单的封装,让它lazyload了,后面我也会谈谈前端lazyload的一些方法。
总结
Algolia给小型项目提供了一个很好的搜索解决办法,虽然数据中心节点在海外但我的使用体验还是非常好的,结果基本都是秒出。